.png)

漫谈大模型与图书馆应用
2024年05期【社区博客】
“社区博客”是云瀚社区分享技术洞察与实践体会的专栏。本栏目专注于探讨图书馆技术应用与思考,旨在促进深入交流,洞察技术在实际中的应用效果、价值及潜力。如您有思考见解,诚邀投稿至calsp@libnet.sh.cn。
漫谈大模型与图书馆应用
/方洋(深圳市海恒智能股份有限公司)
一、前言
2022年11月30日,ChatGPT的发布引爆了本次人工智能的浪潮。每一个接触ChatGPT的人都为其强大的自然语言处理能力而惊叹,从遵循理解用户指令到生成逻辑严谨的长篇答案,相比于小模型,大模型涌现出了过去不具备的能力:上下文学习、指令遵循、逐步推理,让机器对于文本信息的理解能力进行了一次全面的升级。这些信息不仅包括了机器能够从外部获取的客观信息,也包括了用户指令。这些信息的形态也不再受限,可以是结构化的或非结构化的,大模型都能够在一定程度上完成任务。随后,“多模态大模型”再一次给科技圈带来了震撼。多模态大模型在情感分析、问答对话、音视频编辑等场景下表现出了强大的能力。模型的升级为图书馆的人工智能应用带来了弯道超车的机会。借助大模型技术,图书馆和厂商有机会重塑图书馆的服务方式。
二、图书馆大模型应用类型与技术路径
当前图书馆领域已经有一些大模型应用场景落地,比如智能咨询。此类应用在技术层面已较为成熟,跨行业通用性强,可以认为是一种“通用类应用”。图书馆可以通过使用这类应用来提升用户体验。这类应用能够较便捷地被集成进现有的图书馆服务体系中,部署过程相对简单,为图书馆的智能化升级提供了一条快速通道。
除此之外,还有“行业类应用”和“定制化应用”。“行业类应用”体现了图书馆行业大模型应用的差异化,具有行业特点。例如针对图书馆资源管理(采、编、典、流)、读者行为分析、文献检索等方面的应用。行业类应用的部署可能需要特定的行业知识和技术支持,以确保与图书馆的业务流程和数据结构紧密对接。
“定制化应用”体现机构竞争化优势,在个性化和深度整合方面更进一步,它是针对图书馆独特业务需求、利用特定数据集而开发的,如基于特藏和专属数据的开发应用。这类应用需要深入地融合图书馆的数据和业务,其开发和部署可能更为复杂和耗时。
三类应用在落地过程中的技术路径有所区别。很多场景下,图书馆可以直接调用基础大模型,跳过模型训练和私有化部署,即可完成大模型应用。以下是一些常见技术的路径。
1. 提示词工程
提示词可以简单理解为输入给大模型的内容,是模型对于外部世界获取信息的渠道,是往往被人们低估的一种技术。一个优秀的提示词可以在不对模型进行训练的情况下大幅提高大模型处理复杂任务场景的能力,如问答和算术推理能力,或实现和大模型或其他生态工具的高效接轨。
一段优秀的提示词通常包括以下几个部分:
指令:想要模型执行的特定任务或指令。
上下文:包含外部信息或额外的上下文信息,引导语言模型更好地响应。
输入数据:用户输入的内容或问题。
输出指示:指定输出的类型或格式。
2. 检索增强生成
检索增强生成(RAG)是指对大模型输出进行优化,使其能够生成并引用训练数据之外的权威知识库中的信息。在大模型强大的功能基础上,RAG将其扩展为能访问特定领域或组织的内部知识库,这样就无需重新训练模型。这是一种经济高效地改进大模型输出的方法,以保持相关性、准确性和实用性。
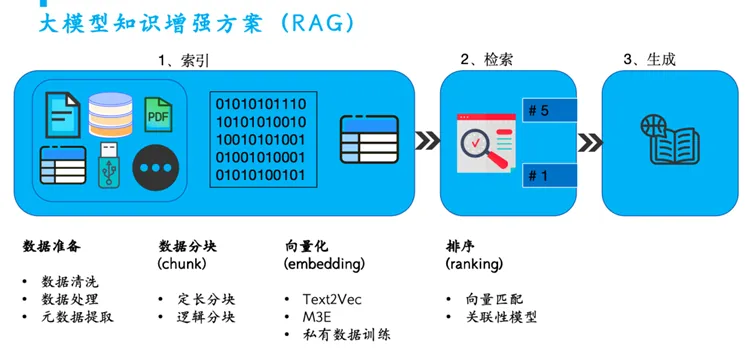
以上面的RAG方案为例,在数据准备阶段,需要对数据进行合理的清洗与预处理,以保证原始数据质量。接着根据数据特性进行切分并进行向量化处理。在信息检索阶段,召回的准确率是至关重要的一环。通过混合检索、重排等算法,对于召回的上下文信息进行处理,可以将更加准确的信息提供给大语言模型,减少幻觉出现的可能。
3.模型微调
模型微调相比前两种路径复杂,对开发者的技术要求、数据要求相对较高。一般来说,在以下几种情况下,可以对模型进行微调:1)由于提示词工程的局限性,模型对输入序列长度有限制,可能导致推理成本增加和输出质量下降。因此模型微调是能将提示词作为“技能”或者“任务”训练给模型的一种方式。2)特定领域的性能提升:对于特定领域,如医疗、法律,如果有该领域的大量数据,可以对模型进行微调以提升某些特定能力。
在图书馆场景下,是否需要进行模型微调?这并没有一个明确的答案。有的图书馆希望将书籍、教材、电子资源等,通过模型微调的方式,让大模型进行学习,从而可以问答关于这些书籍的任何问题。但目前看来,这种“学习”方式的效果可能不能令人满意。我们曾与合作伙伴一起尝试将一本长篇小说加到模型的预训练数据集中,结果收效甚微。小说中某一个出现的知识点,在上T级别的数据集中,如同大海中的一滴水,产生的影响太有限了。当然,我们依然在不断探索更好的技术路径去实现相关的需求。
4.技术组合
除了以上提到的技术方案外,还有其他一些技术组合方式可以实现图书馆大模型的应用。以下是一些尝试:
(1) 虚拟数字人+检索增强生成+大模型(DH+RAG+LLM):
通过虚拟数字人技术,为馆员构建一个仿真的形象,使读者能够与虚拟数字馆员进行拟人的交互。结合检索增强生成的能力,从知识库或者业务系统中获取信息,并根据这些信息回答用户的问题。这种技术组合可以提供更加个性化、互动性强的图书馆服务体验,增强用户的参与感和满意度。海恒智能在本轮科技浪潮中首个大模型应用尝试也是此类产品“小海豚数字馆员”。
(2) 光学字符识别+大模型(OCR+LLM):
AI视觉盘点是一种将大语言模型和传统OCR技术结合起来的技术产品。由于OCR识别后的文字容易产生误差,利用大语言模型进行文字矫正后,图书识别的准确率能有所提高。这种技术组合可以有效提升图书馆数字化管理的效率和准确性。目前在海恒的AI视觉盘点中,通过这项技术优化,将准确率提到了三到五个百分点。同样的技术我们目前正在图书馆藏品数字化、自动采编的流程中进行实践研究。
通过不同技术的组合和创新,图书馆可以进一步升级服务手段、强化原有的服务能力,提供更加智能化、个性化的服务。
三、图书馆大模型应用业务场景与应用效果
图书馆有大量业务场景可以嵌入大模型能力。根据个人研究,下表列举出目前已经落地或正在落地、可展望实现的业务场景。

四、图书馆人工智能应用落地建议
1.打好数字化与信息化基础
图书馆人工智能应用的成功实施依赖于扎实的数字化和信息化基础设施。在大型模型的训练与推理中,高质量的数据资源是核心要素。图书馆的数据基础和信息管理系统扮演着关键角色,它们负责图书、期刊、论文、档案等资源的数字化管理以及读者信息、借阅记录等的信息化处理。这些系统不仅确保了数据的完整性和可访问性,而且为人工智能技术的应用提供了丰富的数据资产和信息环境。具备这些条件,人工智能技术才能得到有效利用,并在图书馆服务的各个环节中实现其最大的效能和价值。
2.领域专家与技术专家协同
领域专家和技术专家之间的密切合作是确保人工智能合理应用的关键。领域专家,如图书馆员、信息专家和学科馆员,深谙图书馆业务需求和用户行为,他们对图书馆的运作和服务有深入的了解。而技术专家,包括人工智能专家、数据科学家和软件工程师等,具备先进的技术知识和技能,能够将人工智能技术与图书馆实践相结合,为图书馆的发展注入新的活力。只有两者紧密携手,共同探索解决方案,才能够更好地满足用户的需求,推动图书馆向着智能化、高效化的方向发展。
3.行业通力合作
合作是智慧图书馆人工智能应用的关键。为了推动人工智能技术在图书馆领域的落地应用,图书馆需要与行业伙伴通力合作。这种合作关系不仅能够提供必要的技术支持和资源,还能够分享实践经验,从而加速人工智能技术在图书馆中的应用。目前,云瀚联盟已经启动了项目池管理,联盟中的图书馆机构与企业合作,共同探索更多的图书馆创新应用场景,进一步促进了智慧图书馆的新发展。
4.目标明确,不盲目追逐技术
目前,人工智能的发展速度远超预期,新技术如雨后春笋般迅速涌现,但其中部分被夸大的宣传容易引发从业者产生不切实际的期望。在图书馆中,应用人工智能技术需要从图书馆自身业务出发,对现有的繁琐、耗时的业务流程进行梳理,整合线上和线下的读者服务,以及系统与接口能力。最终的目标是根据实际需求将业务与技术有机融合,以实现更高效、更智能的图书馆服务。
以大模型技术为代表的生成式人工智能在图书馆的应用刚刚起步,目前正逐渐落地。图书馆的需求与科研机构大模型研究方向、科技企业产品方向正逐渐靠拢。在这过程中,业务与技术将不断碰撞,新业务场景和应用形态也会不断涌现。2024年作为人工智能大模型应用的元年,相信会出现越来越多的新颖且实用的应用,更好地服务馆员与读者。