.png)

DeepSeek等主流大模型图书馆应用场景对比测试
2025年03期【社区交流】
供稿:方旭光(杭州麦达电子有限公司)
2025年春节期间,DeepSeek-R1的发布在AI领域投下了一枚深水炸弹,引发了业界的广泛关注。本文通过对比实验,初步探讨DeepSeek等当前主流大模型在图书馆应用场景个别任务中的表现,实验结果与结论仅供参考。
评测时间:2月14日-2月19日
评测模型:
- DeepSeek-V3/R1/Janus Pro(火山平台/阿里百炼)
- 智谱(GLM-4-Plus/GLM-4V-Plus)
- 豆包(Doubao-pro-32k)
- 通义千问(Qwen-max-latest/omni-turbo)
任务一:实体关系提取与知识图谱构建
任务描述:对《西游记》1-3回文本进行实体与关系提取,并根据提取的实体与关系生成可视化的知识图谱。
实验结果:
1. 运行花费与耗时

总花费: 智谱(GLM-4-Plus)>通义千问(Qwen-max-latest)>DeepSeek-V3(火山平台)>豆包(Doubao-pro-32k)
总耗时:豆包(Doubao-pro-32k)>通义千问(Qwen-max-latest)>DeepSeek-V3(火山平台)>智谱(GLM-4-Plus)
2. 节点提取
- DeepSeek V3 共提取了26个节点,节点类型包括deity(神仙)、character(角色)、location(地点)、artifact(神器)和skill(技能)。提取了23对关系。
- doubao-pro-32k 提取了80个节点,数量最多,包括了地点、角色、神祇、神器、技能、事件等。但存在同一节点的不同形式表述,有所重复。提取了85对关系。
- Qwen-max-latest 提取了28个节点。能对节点之间关系有所解释解读。提取了28对关系。
- GLM-4-Plus 提取了32个节点,并对节点关系进行了解读归纳。提取了27对关系。
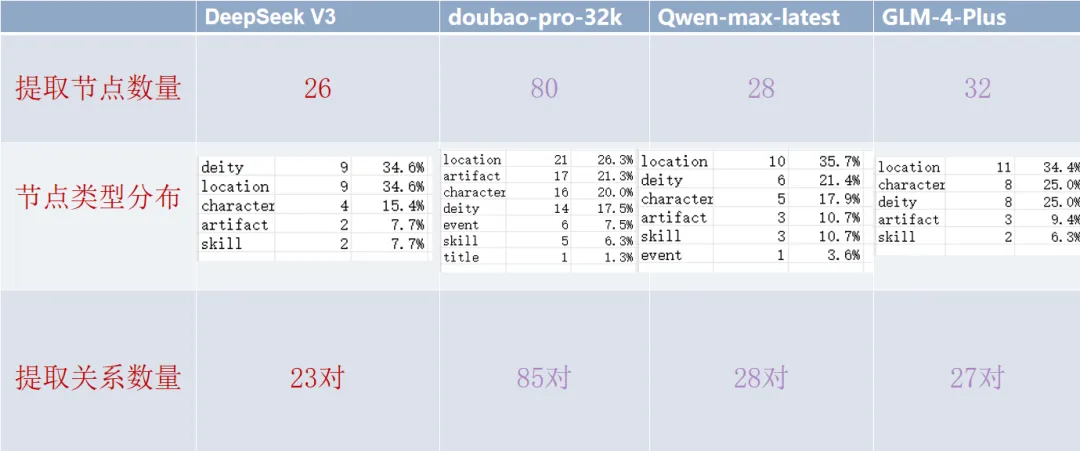
DeepSeek V3-节点与关系提取展示


doubao-pro-32k -部分节点与关系提取展示
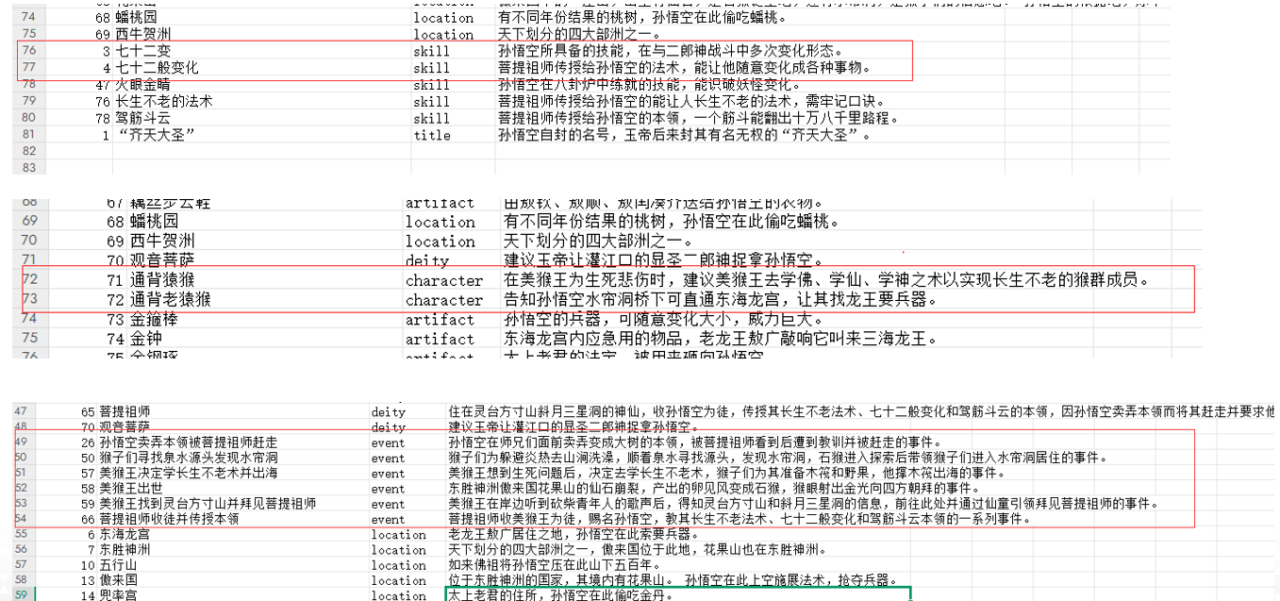
Qwen-max-latest 关系提取展示

GLM-4-Plus 关系提取展示

3. 节点关系可视化
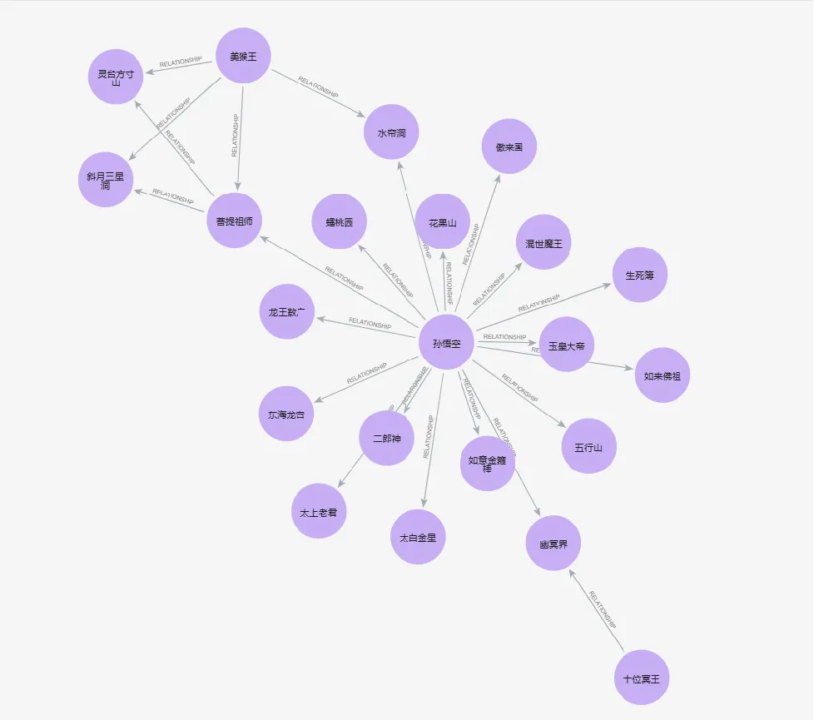
大模型提取关系节点后由图数据库Neo4j自带组件生成可视化图谱,实验结果如下:
- doubao-pro-32k 可视化网络关系分散,未能形成以孙悟空为中心的核心人物实体关系网络
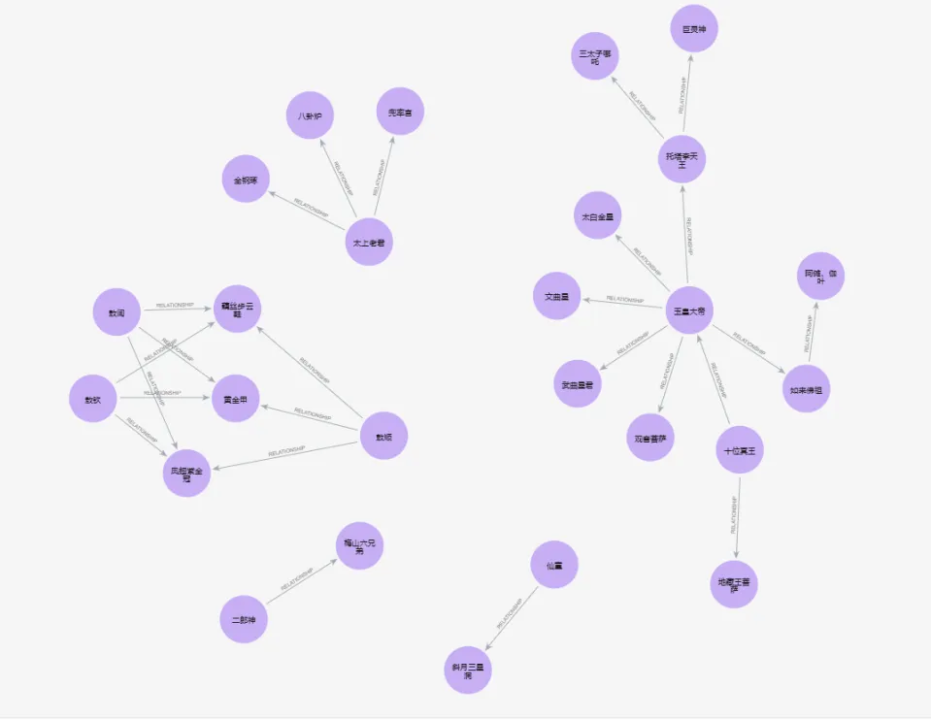
- DeepSeek V3:较好的形成了以孙悟空为中心的以人物为主的实体关系网络
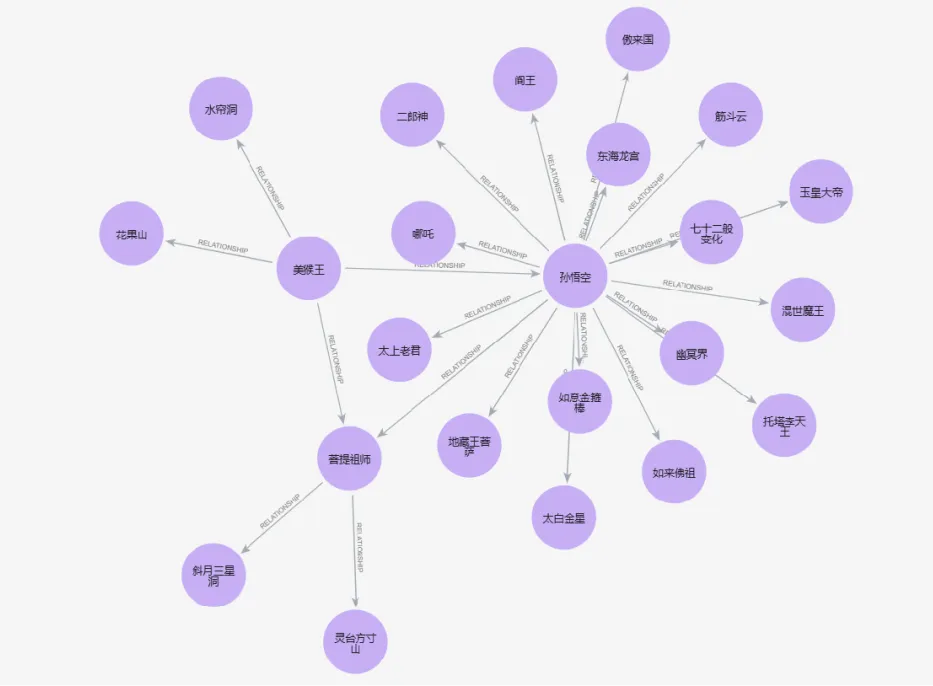
- GLM-4-Plus:较好的形成了以孙悟空为中心的包括人物、地址为主的实体关系网络
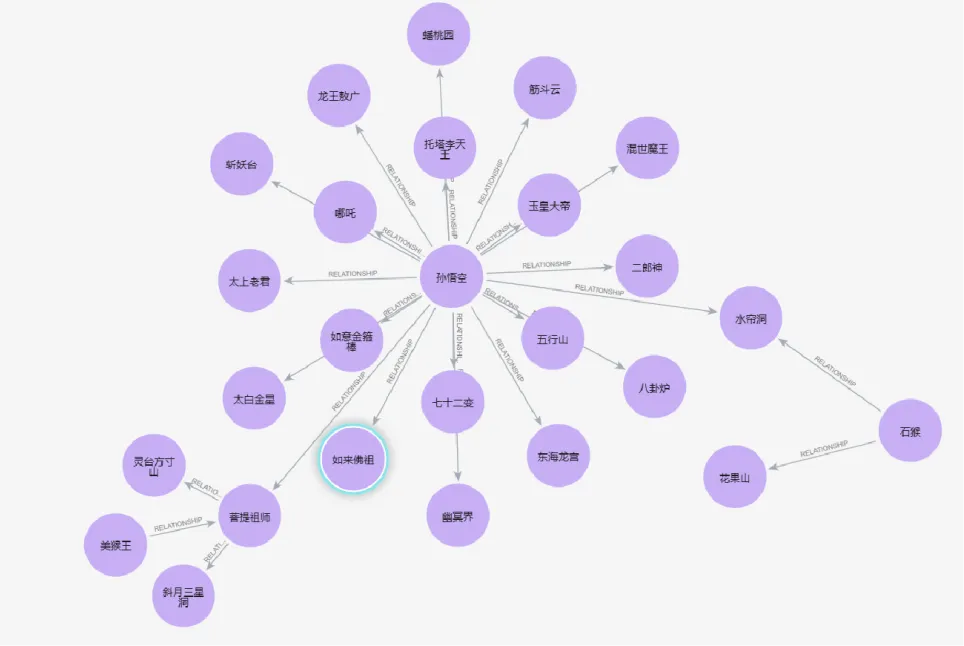
- qwen-max-latest:较好的形成了以孙悟空为中心的包括人物、地址为主的实体关系网络
结果分析:
DeepSeekV3和GLM-4-Plus均在无人工干预情况下完成节点与关系的提取,通过可视化图谱可见形成的图谱基本符合预期。QWen-Max在提取节点与关系时基本符合预期,但是第一次输出时丢失重要节点,导致输出图谱发散,人工介入第二次提取后修正了错误。Doubao-pro-32k在提取时,未做相似节点的合并去重,导致输出节点过多,在形成图谱时发散,这类问题需要进行二次节点合并来解决。
特别说明:在构建长文本的知识图谱时,需要解决内容分段与循环去重并问题,同时结合样本数据,可以搭建不同领域的知识图谱。基于目前大模型的能力,已经可以快速完成知识图谱基础内容的提取与搭建,具备一定的实用能力。
任务二:作者关键信息提取
应用场景:辅助采访
任务描述:从提供的作者生平简介文本中识别并提取关键字段信息,以将非结构化的文本数据转换为结构化的格式。
实验1
作者简介:A,女,汉族,1986年生于重庆市璧山县。法学博士,西南政法大学外语学院副教授。学术研究方向:法律语言学、环境与资源保护法学和国际法研究。作为主研人员参与国家社科基金、省部级科研项目多项,主持校级青年项目一项,主持校级在线开放课程一项,公开发表CSSCI论文数篇,在外文期刊发表论文数篇,已出版学术专著《中英环境影响评价制度比较研究》。小说《黄金时代》《未来世界》两度摘得“《联合报》中篇小说大奖”。
Prompt:根据提供的导师信息,提取并分析以下字段:姓名,出生年月(格式:YYYY),出生地址,毕业学校,在职岗位一级,在职岗位二级,职称,学历,专业领域,研究领域,获奖经历,专著作品,论文 请将提取的信息以JSON格式返回,确保字段名称与上述一致。如果某些信息缺失,请将对应字段值设为null。 示例JSON格式:{ “姓名”: “张三”, “出生年月”: “1980-05-15”, “出生地址”: “北京市”, “毕业学校”: “清华大学”, “在职岗位一级”: “西南政法学院”, “在职岗位二级”: “外语学院” “职称”: “教授”, “学历”: “博士”, “专业领域”: “计算机科学”, “研究领域”: “人工智能”, “获奖经历”: “人工智能,教育部优秀科研成果奖”, “专著作品”: “深度学习导论,深度学习导论”, “论文”: “基于深度学习的图像识别研究,基于深度学习的图像识别研究” } 说明: 如果某些字段无法从提供的导师信息中提取,请将其值设为null。 确保JSON格式正确,字段名称与上述一致。 如果信息中包含多个条目(如获奖经历、专著作品、论文),按逗号分隔。
实验结果:


- DeepSeek R1:“在职岗位”(一级二级)未正确分析提取,“获奖经历”不够准确,“论文”未正确提取
- doubao-pro-32k:“获奖经历“未正确提取
- Qwen-max:“获奖经历“表述重复
- GLM-4-Plus:”毕业院校“为模型猜测
实验2
作者简介: 王小波(1952—1997),中国当代作家。
1952年出生于北京,1978年考入中国人民大学,1984年赴美国匹兹堡大学东亚研究中心求学,回国后先后在北京大学、中国人民大学任教,1992年成为自由撰稿人。小说《黄金时代》《未来世界》两度摘得“《联合报》中篇小说大奖”,电影剧本《东宫·西宫》获“马德普拉塔国际电影节最佳编剧奖”。1997年4月11日病逝。
代表作有杂文集《一只特立独行的猪》《沉默的大多数》,小说《黄金时代》《白银时代》《红拂夜奔》等。
实验结果:


- DeepSeek R1:“在职岗位”(一级二级)为猜测
- doubao-pro-32k:“在职岗位”(一级二级)为猜测
- Qwen-max:“在职岗位”(一级二级)为猜测
- GLM-4-Plus:“在职岗位”(一级二级)正确分析, “学历”为猜测,“专业领域”“研究领域”补充分析正确
任务三:自动分类
应用场景:学位论文、期刊论文自动分类
任务描述:根据题名与摘要,依据中国图书馆分类法进行文章分类。
实验案例
题名:The Heterogenous Effects of Occupational Licensing on Labor Market Outcomes: Three Chapters(职业许可对劳动力市场结果的不同影响:三章内容)
文摘:This dissertation is composed of three chapters focusing on the heterogenous effects of occupational licensing on the labor market outcomes including wages, hours worked and employment.The first chapter, “The Labor Market Effects of Occupational Licensing in the Public Sector”, examines the influence of occupational regulation for public sector workers. The study initially……
Prompt: 根据以下提供的论文题名和摘要,使用中国图书馆分类法第五版(CLC-5)确定一个最合适的分类号:论文题名:[用户输入的论文题名] 论文摘要:[用户输入的论文摘要] 任务:
1. 仔细阅读并理解论文题名和摘要的内容。
2. 应用中国图书馆分类法第五版(CLC-5)的规则,为该论文提供一个最精确的分类号。
3. 根据题名和摘要中的关键信息,确定论文的主要研究领域或主题。
4. 确保所提供的分类号是CLC-5中的有效分类号,并且最符合论文内容。
5. 只返回分类号,不返回任何说明。
实验结果:

整体上分类基本准确,都能控制在CLC-5版范围之内,并能稳定输出。分类的结果与输入文本的内容特征有较大关系,在同等条件下,Qwen-max和GLM-4-Plus相对更为精细。
任务四:多模态内容提取
应用场景:用于自动审核,校验元数据与对象文件是否一致。
任务描述:识别图片信息并对关键字段进行提取,自动化生成结构化元数据。
实验案例

Prompt:提取图片里分类号,单位代码,密级,学号,学位论文标题,中文,英文,申请人姓名,指导教师,专业名称,研究方向,所在学院,论文提交日期,论文提交日期(按yyyy-MM-dd),并且按照JSON的格式展示
实验结果:


Doubao-pro-32k、Qwen-omni-turbo、GLM-4V-Plus进行了正确的信息提取,DeepSeek Janus Pro提取了正确的分类号、单位代码、论文标题,其他错误。
除了DeepSeek Janus Pro外,其他大模型都也准确识别印刷体的图片内容,并都能准确识别图片中的字段内容,并完成格式文本的转换,对于格式文本的图片内容提取具有较高的实用能力。
任务五:文言文翻译
实验案例
原文:公字元直,曾祖去惑,皇單于大都護府士曹參軍。祖儁,皇亳州臨涣縣丞,贈亳州司馬。父意,皇博州聊城縣令,贈右庶子。皆富天爵,而卑宦名。藴而必發,藂乎其後。公自初仕至于得謝,凡十七任。以簡廉直清、敦仁愛人以莅之,是能導善迎休,保有祿位。
Prompt:
你是一位精通古代汉语和现代汉语的语言专家,擅长将文言文准确、流畅地翻译成现代汉语。请将以下文言文段落翻译成现代汉语,并确保翻译内容符合原文的意思和语境,同时尽量保持语言的自然和流畅。
翻译要求:
1.保持原文的意思和语境,避免过度意译或遗漏重要信息。
2.尽量使用现代汉语中常见的表达方式,确保翻译结果易于理解。
3.如果原文中有典故、专有名词或特殊表达,请在翻译后附上简要说明。
4.如果原文有多个可能的解释,请提供最合理的翻译,并简要说明其他可能的解释。
实验结果:
DeepSeek-R1未进行典故解释,但是内容表达准确。

实验总结与思考
1、目前大语言模型已经基本具备了在图书馆领域多点应用的基础能力,特别是在内容提取、文本分类方面,可以结合图书馆应用的实际需要来做集成,如辅助采访、自动编目、自动审校等业务,随着大模型技术的快速迭代,预期使用效果会逐渐接近人工参与的水平,使用成本会进一步降低。
2、DeepSeek V3与参与测试的大模型之间在文本处理领域能力接近,部分差异基本上可以通过调整提示词来对齐能力,可根据实际使用场景与成本考虑选择使用的大模型。
3、对于知识图谱的构建,虽然还有一些问题需要解决,但是可以看到通过大模型来快速构建知识图谱的前景,结合多模态能力,在不久的将来,基于领域知识图谱的构建、导航、应用,在图书馆领域会有很多的使用场景可以落地。
4、DeepSeek Janus Pro由于在2025年1月在发布,所以目前在多模态能力稍弱,可以跟踪其后续迭代版本,相信应该可以跟上甚至超期其他同类模型。
5、文本翻译,包括各种语种的双向翻译各大模型都已经很成熟,具备在绝大部分场景的实用能力。
(点击查看视频)