.png)

RAG检索增强生成技术在图书馆的应用
2024年08期【行业交流】
供稿:陆奕(仰格信息)
大语言模型(LLM)已经成为我们生活和工作的一部分,它们以惊人的能力改变了我们与信息互动的方式。然而,它们并非无懈可击。大语言模型在回答问题时可能会产生误导性的 “幻觉”,依赖的信息可能过时,处理特定知识时效率不高,缺乏专业领域的深度洞察,在特定问题的推理能力上也有所欠缺。正是在这样的背景下,检索增强生成技术(Retrieval-Augmented Generation,RAG)应时而生,成为当前AI技术应用的重要趋势。充分运用RAG技术,可将图书馆丰富的文献数据资源与大语言模型强大的AI处理能力相结合,全面提升读者在图书馆资源搜索、资源阅读等场景的体验,从而使图书馆的专业文献资源,在AI时代发挥更大的价值。
什么是RAG
RAG是指对大语言模型输出进行优化,使其能够在生成响应之前引用训练数据来源之外的权威知识库。大语言模型通常采用海量数据进行训练,使用数十亿个参数为回答问题、翻译语言和完成句子等任务生成原始输出。而在大模型本就强大的功能基础上,RAG 将其扩展为能访问特定领域或组织的内部知识库,无需重新训练模型。这是一种经济高效地改进大模型输出的方法,让它在各种情境下都能保持相关性、准确性和实用性。
RAG如何工作
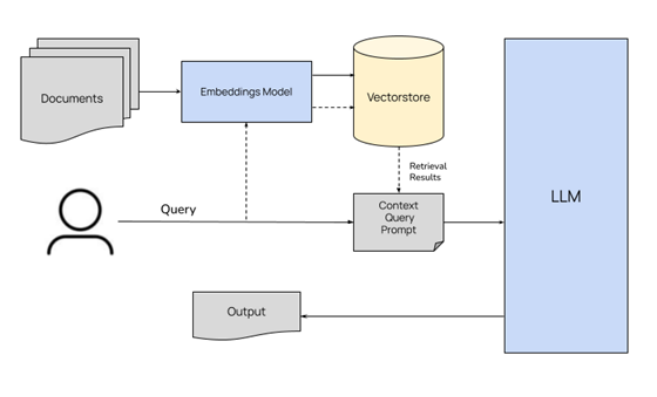
RAG通过检索获取相关的知识并将其融入Prompt提示词,让大语言模型能够参考相应的知识从而给出合理回答。因此,可以将RAG的核心理解为“检索+生成”,前者主要是利用向量数据库的高效存储和检索能力,召回目标知识;后者则是利用大语言模型和Prompt提示词工程,将召回的知识合理利用,生成目标答案。
完整的RAG应用流程主要包含两个阶段:
数据准备阶段:数据提取——>文本分割——>向量化(embedding)——>数据存入向量库
应用阶段:用户提问——>数据检索(召回)——>注入Prompt提示词——>LLM大语言模型生成答案
图书馆如何应用RAG
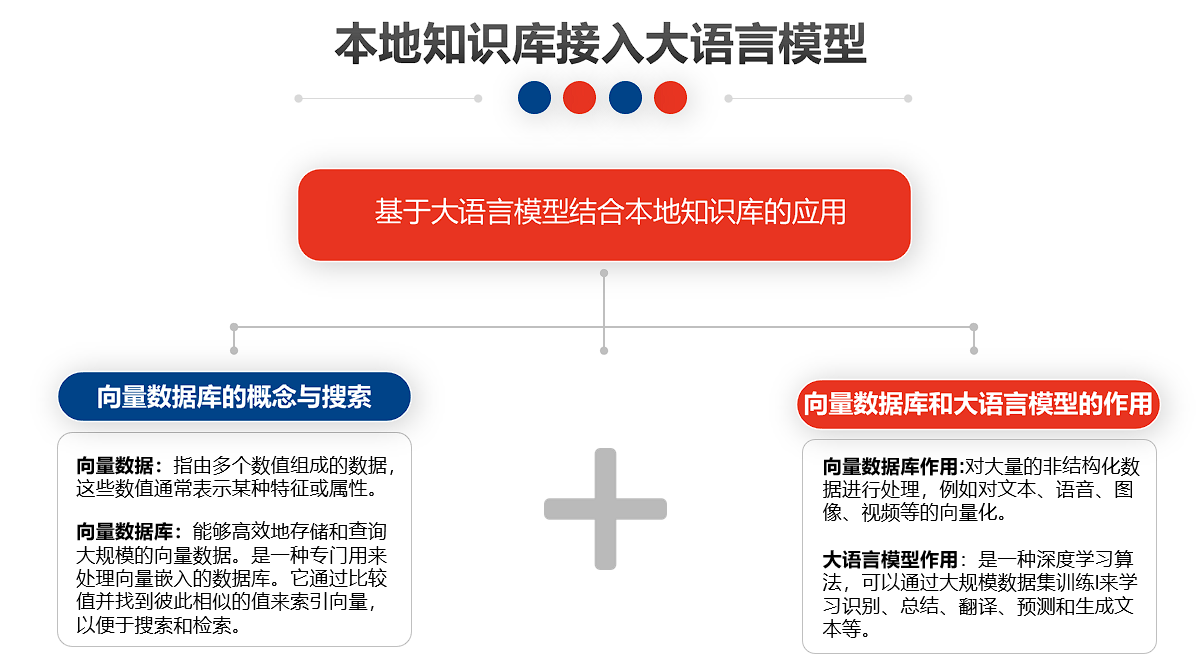
RAG技术是一种结合信息检索和文本生成的技术。在图书馆中,图书馆馆藏当中存在大量的学术文献,可以将这些学术文献通过专业的向量化工具进行切片存储在向量数据库当中,形成一个本地知识库,再将本地知识库与大语言模型进行结合,当用户提出问题时,系统能够根据用户的问题检索图书馆的数字资源,并生成准确的回答。这可以大大减少用户查找信息的时间,并提高回答的相关性。

图书馆应用RAG实际案例
南京仰格信息科技有限公司基于上文的思路,设计研发了RAG检索增强生成技术相关的产品。实现了PDF智能辅助阅读和分析、数据库AI导航助手、资源发现AI检索助手、个人知识中心等创新功能。相关产品已在清华大学图书馆、上海图书馆、南京大学图书馆、西安交通大学图书馆等多家行业机构进行应用。
清华大学图书馆为快速推进人工智能在图书馆的落地应用,于2024年4月28日正式上线了AI阅读助手、AI导航助手应用。通过智能分析PDF文档和数据库内容,提升了师生的阅读和研究效率。两项应用均面向清华全校师生提供服务,上线后收到了读者的良好反馈。
上海图书馆专业服务中心在上图专业服务门户中,也融入了多个AI智能辅助功能。创新性的将大语言模型融入图书馆资源发现服务,实现了对文献检索结果的快速分析功能。并通过打造个性化的读者个人知识中心,提供智能问答等辅助阅读服务,全面提升读者资源检索与阅读体验。
PDF智能辅助阅读和分析
支持读者采用自然语言交互式问答,大语言模型会基于PDF文献全文信息,就读者提问给出相应答案。即使面对英文文献,读者依然可以选择采用中文提出问题,AI阅读助手会在深度理解文献内容后,采用中文回复读者的相关问题。读者可根据AI阅读助手给出的答案,进行二次追问,实现多轮问答对话。可生成文章核心概念的知识图谱。支持基于文章的段落内容,支持手动选择一段话进行提问、分析、翻译。




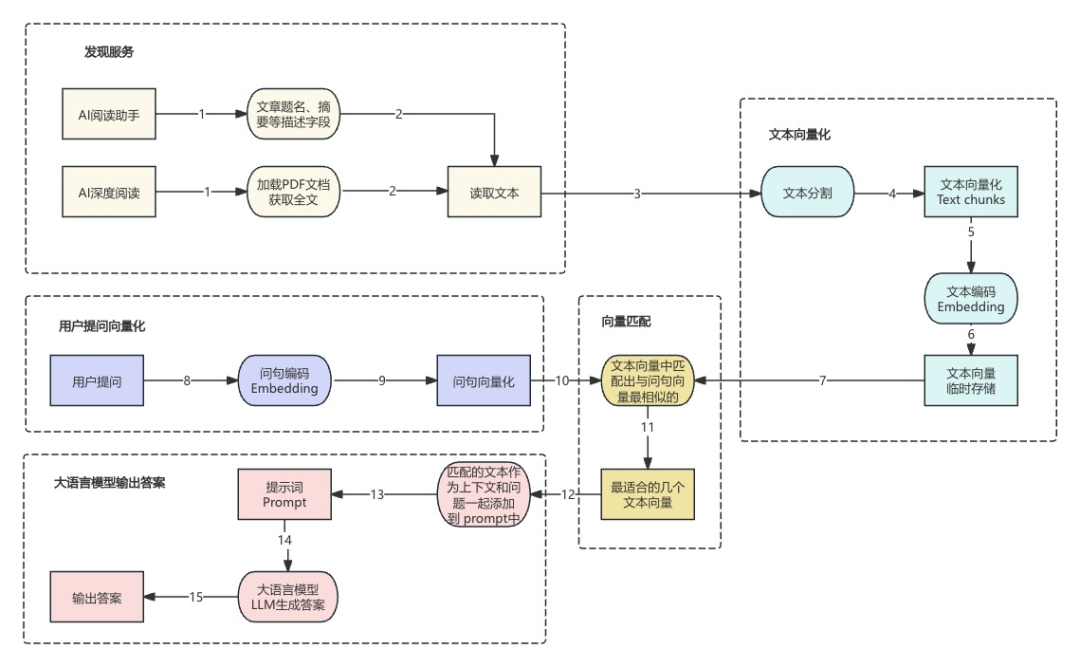
PDF智能辅助阅读和分析工具技术原理
PDF智能辅助阅读和分析工具可加载并解析PDF文档,提取文本内容。通过将文献文本分割成小块并进行向量化编码,生成文本向量并存储。用户在提出问题后,系统将问题编码成向量并与存储的文本向量进行匹配,找到最相似的文本片段。之后结合系统生成的提示词,由大语言模型(LLM)进行互动处理,最终输出答案给用户。PDF智能辅助阅读和分析工具可对接图书馆资源发现服务产品,辅助读者分析发现服务中相关PDF全文文献。
数据库AI导航助手
可以帮助读者以中英文对话的方式,轻松查找所需的数据库资源。AI导航助手能够理解读者的自然语言表达,识别读者的搜索意图,并根据读者的需求进行精准的数据库信息检索。读者无需掌握复杂的检索技巧,只需使用日常交流语言即可进行查询相关资源。


数据库AI导航助手技术原理
数据库AI导航助手采用了RAG检索增强生成技术的扩展方案。用户提出查询问题后,大语言模型理解问题,通过同步执行向量搜索、关键词搜索的模式在备选数据库中搜寻符合用户需求的数据库信息。向量搜索适合于语义查询场景,通过语义匹配向量数据库中符合查询条件的内容。而关键词搜索适合于准确的目标词匹配查询。这两种模式的结合使用,可以有效覆盖大部分用户提问类型。通过结合语义排序模型、权重算法等技术,最终将最符合需求的数据库信息推荐给读者。
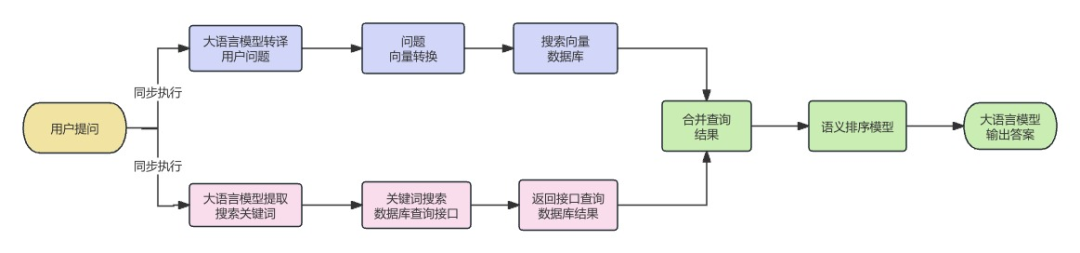
资源发现AI检索助手
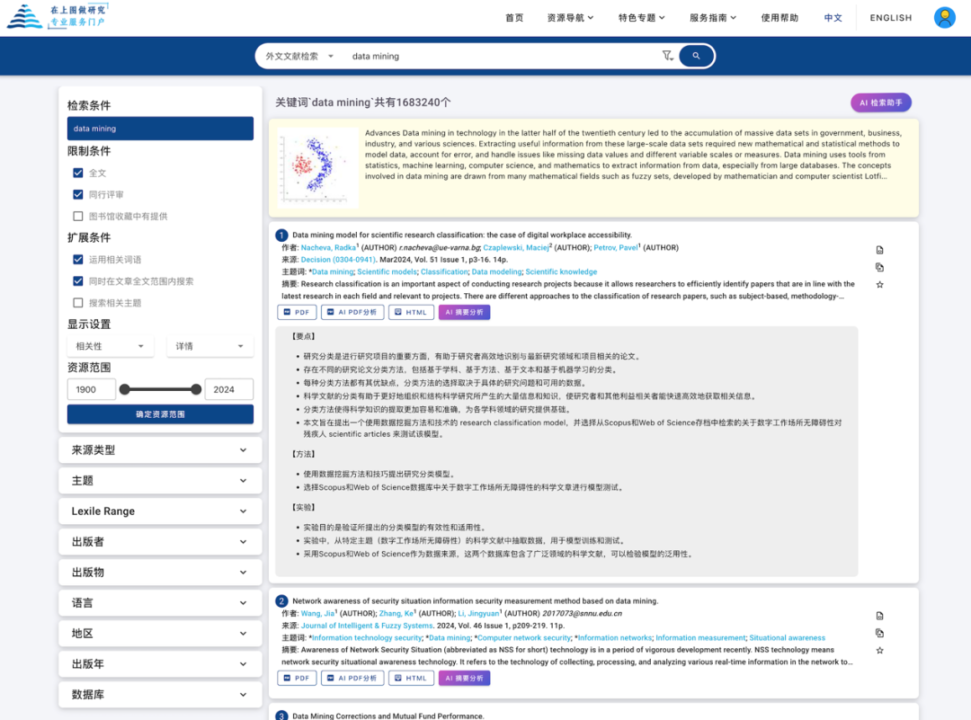
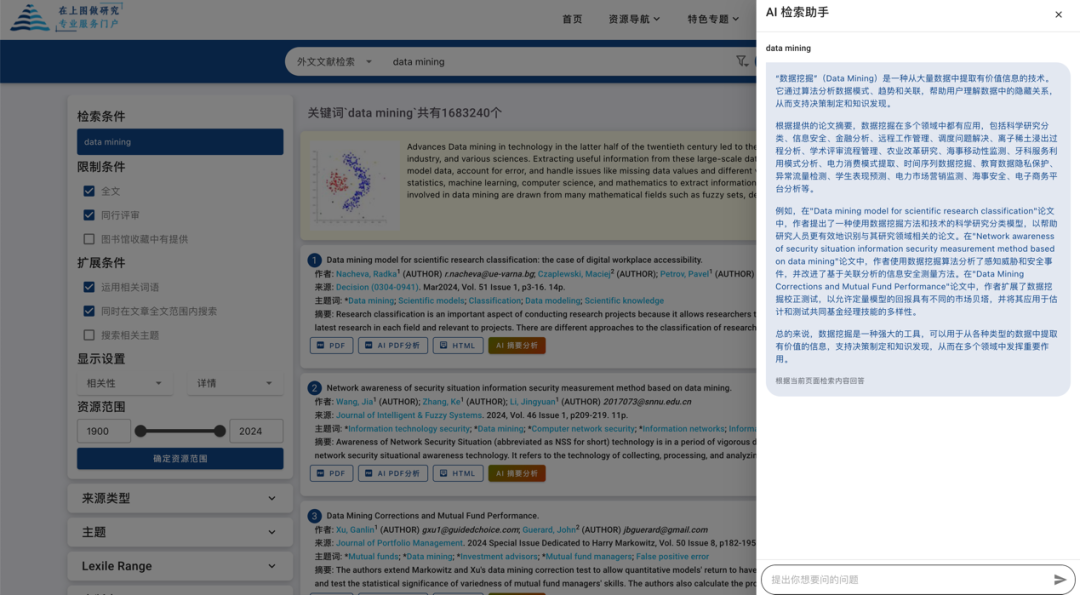
将AI大语言模型与图书馆资源发现服务相结合,全面提升读者资源检索与阅读体验。实现对文献检索结果的快速分析功能,分析文章要点、研究方法和实验结论。可用简短的语言总结文献摘要,为英文文献快速提取简短的中文简介。同时AI检索助手功能可语义分析读者输入的检索词与检索结果,通过分析多篇文献的观点形成综合性的总结。

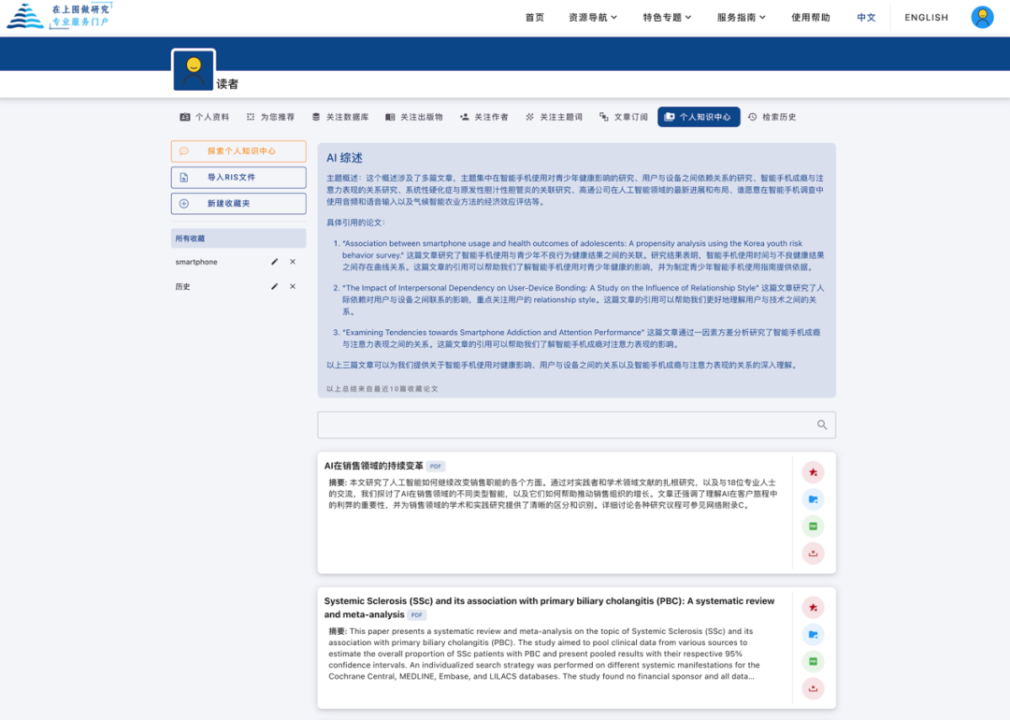
读者个人知识中心
读者个人知识中心是文献收藏夹的升级版本。运用生成式AI大语言模型。读者可以围绕属于自己的个人知识中心文献仓储,进行个性化学术问答。并快速提取个人知识中心内文章的学术主题词、学术研究方法等信息。有效帮助读者进行辅助阅读和研究。
AI可总结读者个人知识中心内的文献信息,提供文献综述。并通过个人知识中心探索功能。引导用户通过提问的方式深度探索个人知识中心内的文献内容。
支持采用中英文自然语言交互方式进行提问,对个人知识中心内文献进行快速定位,并且将外文搜索答案以中文方式翻译给读者,支持对文章进行AI分析和交互式问答。批量反馈多篇文献对于用户问题的相关答案;总结答案知识关系图谱;并可智能提取文献重要属性字段。