.png)

从垂直小智能体到超级智能体:基于驾驭工程的图书馆智能体平台设计与实现
2026年06期【行业交流】
作者:陆奕(南京仰格信息科技有限公司)
随着大语言模型能力趋于同质化,决定智能体能否在图书馆场景稳定落地的关键因素,已由模型本身转向驾驭工程(Harness Engineering)。本文从智能体技术范式的演进出发,剖析“单一超级智能体+资源/方法论双层即插即用”架构的技术原理;在此基础上提出基于驾驭工程的图书馆智能体平台总体设计,阐述其五层架构以及沙箱执行环境、动态子智能体调度、上下文工程、关键节点人工确认、渐进式技能加载等关键机制;并结合文献查询、深度调研与研究报告生成等典型场景,分析该平台为图书馆服务能力带来的提升,以期为图书馆智慧服务体系建设提供参考。目前,云瀚联盟成员南京仰格信息科技有限公司已基于上述理念完成该平台的产品化研发,为业界探索这一技术路线提供了一个可参考的落地样本。
过去两年,许多图书馆在引入大模型服务时不约而同地走了同一条路:为每一类资源单独构建一个垂直小智能体——纸本馆藏一个、电子资源一个、数据库一个,彼此独立运作(见图1)。这种方案在模型能力有限的阶段是务实的选择,但其结构性缺陷也日益突出:平台之上缺乏统一的意图理解与调度入口,读者面对一组功能割裂的小工具,需要自行判断“该用哪一个”;每新增一类资源就要新建一个智能体,扩展成本与使用成本同步攀升;更重要的是,缺乏统一编排使其难以承担跨资源、跨步骤的复杂研究任务。
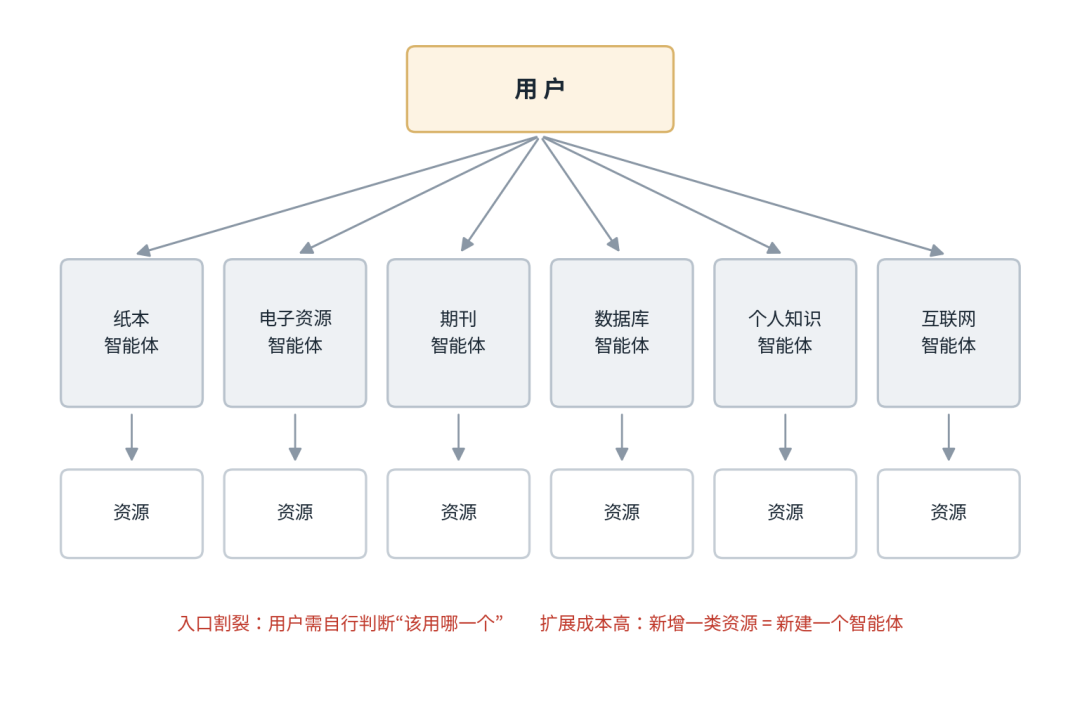
图1 传统方案:一类资源一个垂直小智能体
2026年,随着大模型推理与工具编排能力的成熟,一种新的技术路线成为可能:以一个具备规划、推理与工具编排能力的“超级智能体”统筹全局,按需调用全域资源与领域方法论。本文以一款按照这一路线构建的基于驾驭工程的图书馆智能体平台(Harness Engineering-based Library Agent Platform,下文简称“本平台”)为研究对象,阐述其技术原理、平台架构,并结合典型场景分析其工作流程及为图书馆服务带来的提升。
1 技术原理
(1)从提示工程、上下文工程到驾驭工程
回顾智能体技术的演进脉络:2023-2024年,行业关注的重心是提示工程(Prompt Engineering),即“怎么跟AI说话”;2025年转向上下文工程(Context Engineering),解决“给AI看什么信息”;到了2026年,当各家大模型的基础能力趋于同质化,真正决定智能体能否落地、能否稳定完成重型任务的,已经不再是模型本身,而是驾驭工程(Harness Engineering)——对AI整个工作流的系统性管控。
一个形象的比喻是:大模型是马,Harness是马具。马具不提供动力,但能牢牢牵住方向、稳住步伐,让这匹烈马既能全力奔驰,又始终走在正确的路上。对图书馆而言,这意味着平台不应只是“带工具的聊天机器人”,而应是一个具备完整执行环境、能够稳定执行复杂检索与研究任务的生产级智能体系统。
(2)单一超级智能体与资源/方法论双层即插即用
新范式的核心是用一个主智能体统一承接所有任务:由它理解读者意图、决定调用哪些资源、按什么顺序调用。底层则通过两套机制将图书馆能力以标准化方式供给主智能体调用(见图2)。
一是资源接入层,解决“哪里有数据”。通过MCP(Model Context Protocol)或API等方式,将纸本书目与馆藏、电子资源文章数据、期刊层数据、数据库层数据、个人知识中心文献以及互联网信息等全域资源标准化封装,抽象成主智能体可发现、可调用的标准接口。
二是方法论沉淀层,解决“怎么用这些数据”。馆员的专业Know-How——如何检索科研论文、如何查找纸本馆藏——以结构化文档(Skills)的形式沉淀到平台,成为可复用、可持续积累的领域方法论。
资源接入、方法论沉淀与主智能体编排三者解耦、各自独立演进:新增一类资源只需按规范实现一个接入端,新增一项专业能力只需增加一个Skill,主智能体本身无需修改。这正是该架构具备极强可扩展性的根本原因。
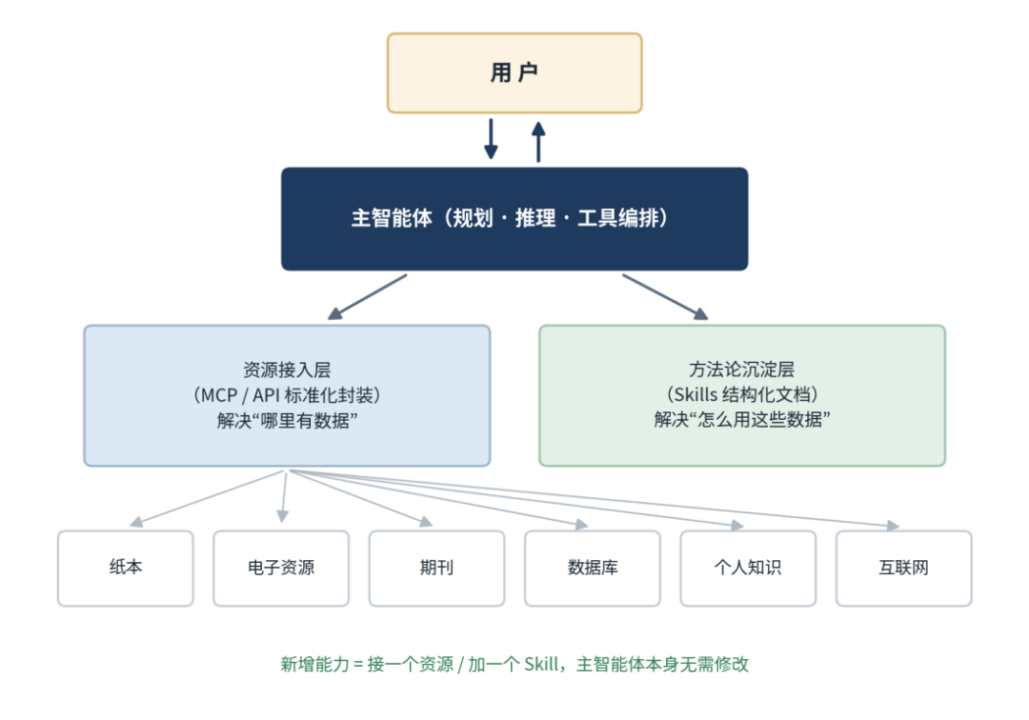
图2 新范式:单一超级智能体与资源/方法论双层即插即用
(3)支撑长任务稳定执行的关键机制
撰写一份研究报告可能涉及数十篇文献摘要、多个数据来源的交叉比对与多轮互联网检索,所需信息量远超单一上下文窗口的容量上限,这正是对话式机器人与生产级智能体之间的分水岭。平台通过一组相互配合的工程机制予以解决:其一,动态子智能体调度——主智能体把复杂任务拆解为若干子任务,按规划顺序逐步拉起子智能体执行,每个子智能体拥有独立上下文、独立工具集与独立终止条件,完成后仅将高密度的关键结论回传;其二,上下文工程——中间结果(文献全文、原始检索结果、图表数据)持久化到文件系统而非占用主上下文,并对编排历史持续自动压缩裁剪;其三,沙箱执行环境——每个任务分配一个隔离的虚拟工作台,划分上传区、工作区与输出区,会话之间零污染、全过程可审计;其四,关键节点人工确认——在研究计划等关键决策点暂停,等待用户确认或修订后再进入执行阶段,避免智能体长时间运行后才发现方向跑偏;其五,渐进式技能加载——Skills按需调入上下文,方法论库即便扩展到数十、上百个,单次任务的上下文成本与响应时延也不会线性上升。
2 平台总体架构
依据上述原理,本平台总体架构自上而下划分为五层(见图3):用户交互层提供统一的自然语言对话入口,向读者屏蔽底层全部复杂性;智能体编排层由主智能体统一调度,结合子智能体逐步分治与关键节点人工确认机制;能力扩展层承载MCP/API资源接入与Skills方法论库;沙箱执行层提供隔离的虚拟工作台,支持文件读写、代码执行与全过程审计;任务交付层负责多格式专业文档生成。各层职责清晰——底层保障长任务稳定执行,中层支撑能力灵活扩展,编排层负责智能调度,交付层保证输出质量。
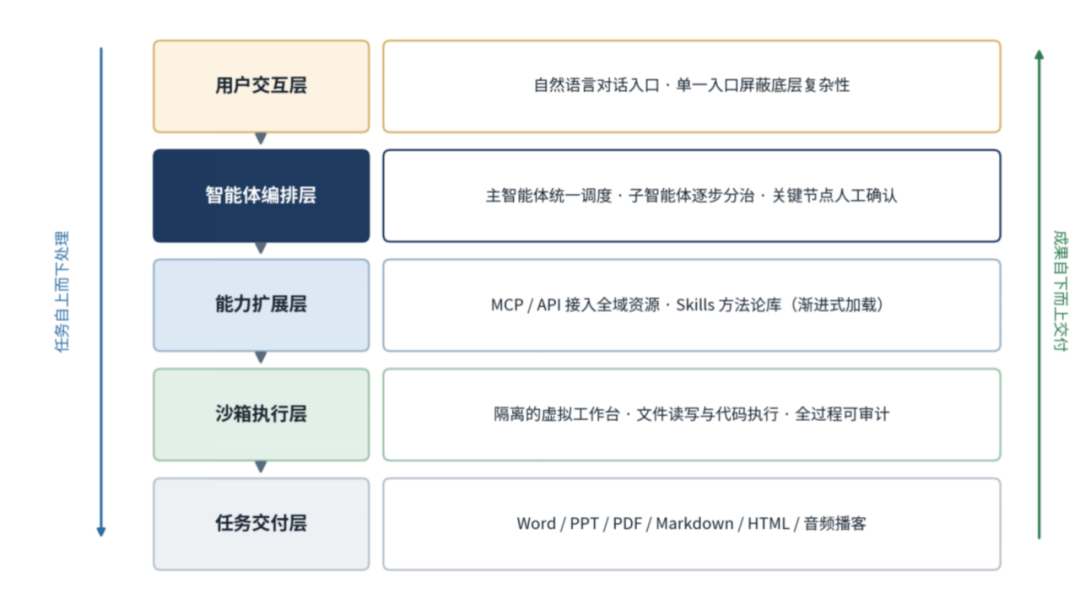
图3 平台五层架构
值得强调的是交付环节的实现方式:Word、PPT、PDF等文件并非由大模型直接生成文本拼接而成,而是智能体在沙箱内以编程方式生成,因此格式严谨、可复现、支持复杂表格与图表,可直接交付使用。平台目前支持Word、PPT、PDF、Markdown、HTML与音频播客等多种输出形态。
3 典型工作流程与应用场景
以一个交叉学科调研需求为例:读者提出“查一下‘量子计算+生物医药’交叉领域的最新研究进展”。主智能体首先生成研究计划大纲——要查哪些库、采用哪些角度、关键检索词、最终产出形式——并暂停等待确认;读者可以直接接受,也可以用自然语言修订甚至完全重定向。确认后进入执行阶段:主智能体在沙箱内按计划依次派出子智能体,先查纸本与馆藏,再查电子资源文章与期刊,继而补充数据库与个人文献,必要时调用互联网检索,上一步的产出成为下一步规划的输入;全部子任务完成后,由主智能体汇总各路结论,在沙箱内编程生成结构严谨的研究报告交付读者(见图4)。
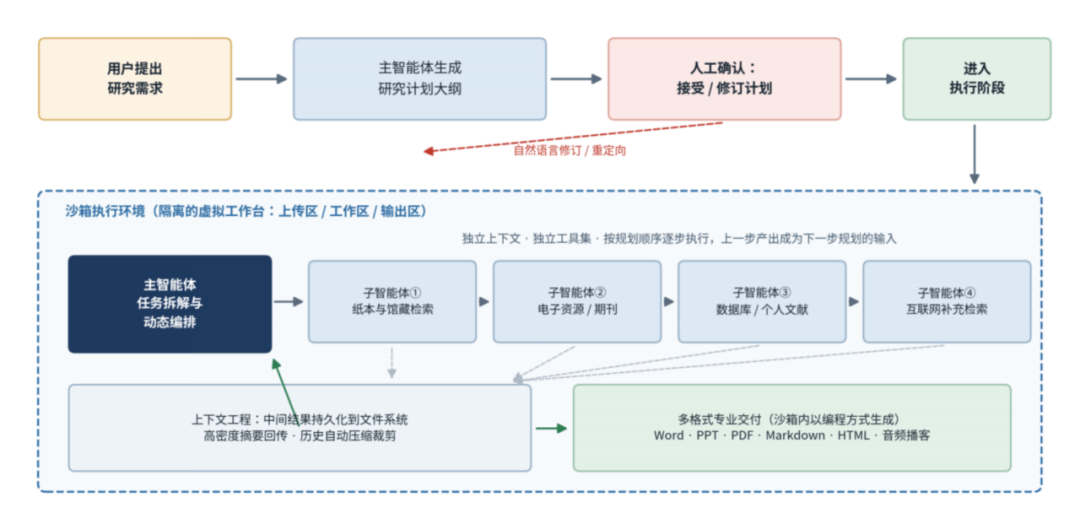
图4 复杂研究任务的执行流程
从服务形态看,平台同时覆盖两类需求:一类是即时问答,如书目检索、馆藏查询、电子资源检索,主智能体直接调用对应资源即可在数秒内完成响应;另一类是长链路研究,如跨纸本、电子、期刊、数据库、个人文献与互联网的综合调研及报告撰写,依托前述机制能够稳定完成长周期任务。内置的标准Skills覆盖文献查询、深度调研、报告输出等最高频的图书馆服务场景,由产品团队与图书馆专家共同设计、统一维护;后续可逐步开放更灵活的Skills编辑机制,支持馆员参与方法论沉淀,使平台的专业能力随业务持续生长。
对图书馆而言,这一架构带来的升级是多方面的。在读者侧,全部馆藏与服务收敛为一个自然语言入口,读者无需学习和分辨多个检索系统,使用门槛显著降低;服务能力也由有限轮次的问答交互升级为可托付的研究任务交付——读者提出需求、确认计划,即可获得一份格式严谨、可直接使用的研究报告。在管理侧,新增资源只需按规范接入一个端点、新增能力只需增加一个Skill,扩展不再意味着重复建设;沙箱隔离与全过程可审计的执行机制,则让AI服务的质量与安全可控可查。在馆员侧,专业检索经验得以以Skills形式结构化沉淀,从个人经验转化为机构的永久资产,馆员的角色也由重复性咨询转向方法论建设与服务设计。
结语
基于驾驭工程的图书馆智能体平台,其本质是以一个具备完整驾驭工程能力的超级智能体,配合图书馆领域方法论沉淀与全资源标准化接入,替代过去由十余个垂直小智能体组合而成的图书馆AI服务体系——既能完成即时问答,也能稳定交付长周期研究任务的成果。这一架构转变的意义不仅在于功能的增强,更在于为图书馆提供了一条可持续演进的技术路径:资源可以即插即用地接入,馆员的专业经验可以以Skills形式不断沉淀为平台的永久能力。随着驾驭工程实践的深化,图书馆智能体有望从“辅助检索工具”真正走向“可托付任务的研究助手”。
目前,云瀚联盟成员单位南京仰格信息科技有限公司已基于上述理念完成该平台的产品化研发并开放试用,实现了与图书馆主要资源的全面对接,为业界探索这一技术路线提供了一个可参考的落地样本。