.png)

美国国会图书馆实验室人工智能规划框架
2024年03期【本期推荐】
《美国国会图书馆实验室人工智能规划框架》由美国国会图书馆实验室高级创新专家Abigail Potter撰写,最早于2022年提出,并于2023年11月进行了更新发布。文件旨在为图博档机构提供实用的指导和战略方针,以应对迅速发展的人工智能技术所带来的挑战和机遇。这一框架为组织提供了清晰而系统的方法,帮助他们在实验和部署人工智能解决方案时,更好地理解其需求、风险和机遇,值得研究参考。

美国国会图书馆实验室人工智能规划框架
自2016年成立以来,美国国会图书馆(LC)实验室一直在探索如何利用新兴技术扩展数字资源的使用。我们很快意识到机器学习(ML),作为人工智能(AI)的分支,是提供元数据并丰富馆藏与用户之间连接的可能方式。实验表明,AI应用在图书馆、档案馆和博物馆(LAMs)所带来的风险与收益均不可忽视,然而,目前的研究大多基于假设。总的来说:
- 图书馆馆藏多样,当前机器学习和AI工具处理起来具有挑战性。
- 新的AI工具不断发布,宣称功能强大。我们从公开测试这些工具中受益,并与他人合作,向他人学习。
- 需制定AI质量标准和政策并传达给合作伙伴和供应商,以支持我们长期向公众提供权威资源的背景。
- 尽管在图博档机构中全面实施负责任的AI尚需数年,但现在是增加实验和跨部门合作的时候,不仅限于组织内部,亦需扩展至整个行业。
为应对挑战,LC实验室一直在制定相关规划框架,旨在支持图书馆对人工智能技术的负责任探索及潜在应用。在宏观层面上,该框架包括三个规划阶段:1)了解、2)实验、3)实施,每个阶段都对支持机器学习的三要素进行评估,分别是:1)数据、2)模型、3)人员。我们设计了一套工作表、问卷和研讨,以聘请/吸收相关单位和员工,以及为未来AI增强服务明确优先事项。这些机制、工具、合作和产品共同构成了AI规划框架。我们分享框架及相关工具的初版,鼓励大家尝试并征求反馈。随着对机器学习规划要素和阶段认知的不断深化,我们将持续对该框架进行优化和更新。
框架中的要素对于图博档机构和联邦部门人员来说很熟悉。它融合了Ryan Cordell、Elizabeth Lorang、Leen-Kiat Soh、Thomas Padilla和Benjamin Charles Germain Lee的研究与建议。同时,该框架受多个评估框架和指南的启迪,诸如国家标准与技术研究所“可信人工智能框架”、“联邦机构数字指南倡议”,以及“国家数字保存协会数字保存级别”。此外,通过与美国总务管理局人工智能实践社区、国家档案管理局创新办公室、史密森尼数据实验室、弗吉尼亚理工大学图书馆以及AI4LAM网络等机构成员的紧密协作,该框架得以完善。该框架最初与梅隆基金资助的“文化遗产云计算”计划一起提出,于2022年在苏格兰格拉斯哥举办的iPres会议上首次分享。
数据、模型、人员
在LC进行人工智能和机器学习规划与实验时,我们将机器学习过程简化为三个主要要素:数据、模型和人员。这些要素如何结合起来,帮助了解应用的技术是否有用、是否符合伦理以及是否有效呢?
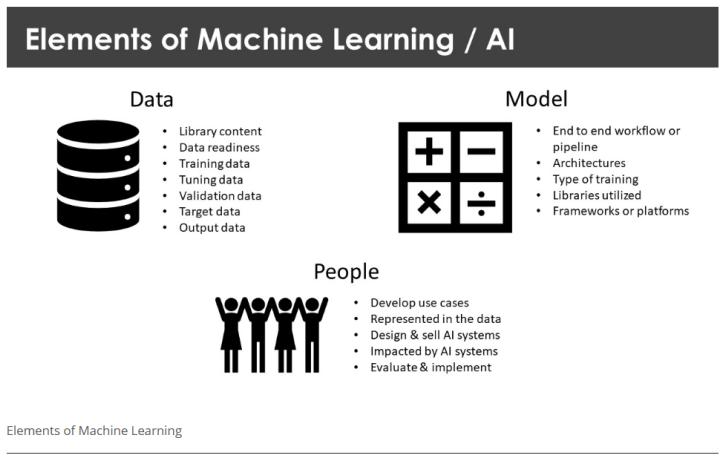
数据
“数据”在机器学习中无处不在。数据用于模型训练,是模型的输入和输出。数据包含模型用于识别和预测的模式(或标签),数据可以验证预测是否正确。在美国国会图书馆,数据通常包括馆藏数据、历史版权数据或立法数据。国会图书馆的数据涵盖所有数字格式,通常在其他地方难以获取。这些现实世界的数据集并不是为了被AI处理而创建的。它们固有的混乱、不平衡、不完整的历史内容会使模型困惑,导致不良或错误的模式识别。关于“最先进”模型或工具性能的发布指标通常是基于当代处理数据,或研究环境中的知名数据集。
模型
“模型”是对机器学习算法中用于训练、处理和预测的一系列复杂技术和工具的统称。机器学习程序能够从数据中学习模式,而无需明确告诉它要处理什么,这一点区别于其他计算机程序。模型的训练方式、训练内容、数据处理方式以及如何将数据提供给用户或其他系统,都决定了模型对特定任务的效果。用于处理语音和文本的模型通常被称为自然语言处理(NLP),计算机科学家已经开发了这些模型超过20年。模型训练的方式、模型数据处理的云架构能力,以及互联网上可用的庞大的训练数据集,都是近期的发展。越来越多的供应商提供AI服务,其中模型经过预训练、微调,并打包到专有的工作流程中。
人员
尽管机器学习是一个技术和数据驱动的过程,但“人员”是机器学习的关键,与“数据”和“模型”紧密相连。人们创建数据,并在数据中被表示,其隐私和权利受到法规和法律的保护。人们设计和开发AI工具以实现特定目标,有些是科学目标,有些是商业目标。员工的专业知识和能力也在机器学习的潜在用例中得到体现。如果某个用例缺乏训练数据,需要人来标记数据集,这增加了新的管理与视角。机器学习系统可能会对人产生积极或消极的影响。人及其所代表的组织对AI系统的质量负责。何时、如何以及是否负责地实施人工智能最终均由人来决定。
AI规划的三个阶段
AI规划框架中考虑了AI系统中涉及的数据、模型和人员。理解、实验和实施这三个步骤阶段需要协同合作,并形成相关文件,为负责任的AI实践和政策制定提供指导。
理解
首先,明确人工智能的使用目的,并了解如何适用于特定的任务、系统或组织。收集不同的观点,重点思考团队计划提供的功能和服务。就脑海中的特定应用案例(用例),共同确立指导原则、评估风险和收益、细化需求、明确优先级、征求专业意见,并了解数据准备情况。
在全面搜集图书馆的AI应用案例时,深入了解某个用例的人员、模型和数据的情况十分有益。我们开发了以下工具和指导,帮助团队完善用例并评估其可行性。
- 制定实施AI的价值观、原则和政策,以指导复杂决策。可以参考美国白宫提出的政府使用AI原则,这是一个很好的起点。
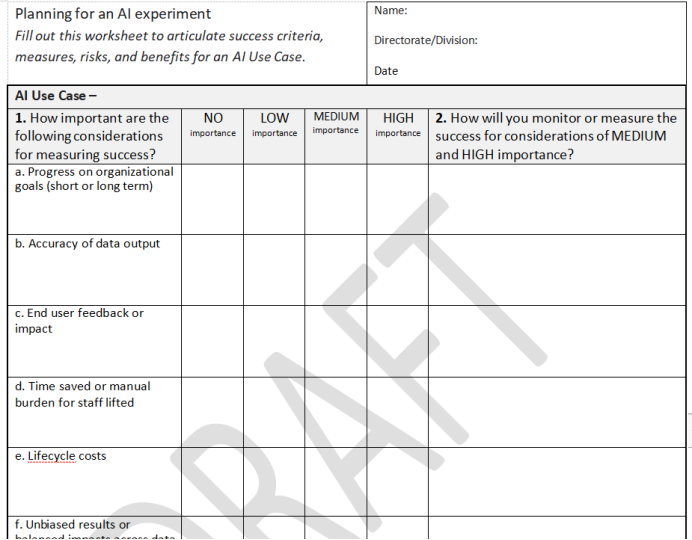
- 创建了“用例评估工作表”(表1),列出可能影响特定用例风险的情形。第二阶段评估明确不同群体的风险和利益,填写特定用例的成功标准(表2)。
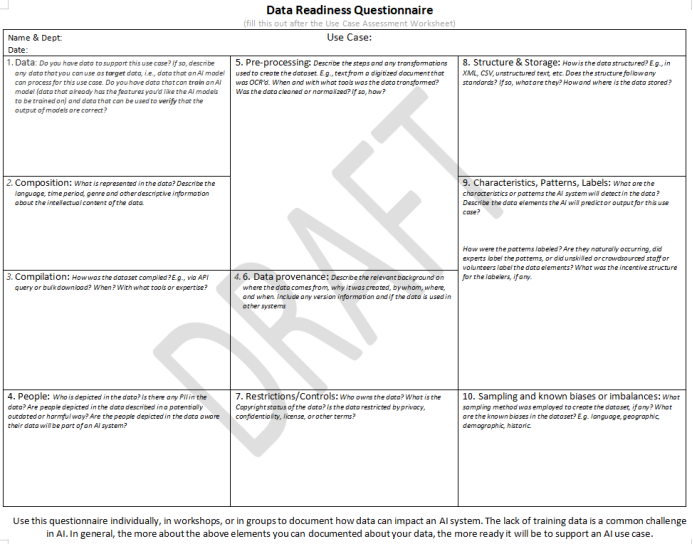
- 模型缺乏可用的训练和评估数据是AI实施的常见障碍。图博档数据本质上是不平衡的,这会影响到AI结果的质量。我们设计了一份工作表(表3),以了解和记录用于AI系统的数据准备情况。
- 成立领域情况讨论组(Domain Profile Workshop),指导应用案例分组,并根据专业水平、风险大小及功能需求确定事项优先级。
在图博档机构中,AI工作的资源和技术支持相对有限。对于风险等级较高的应用案例,其实施往往需要更多的资源和时间投入。实验室开发了理解工具(Understand tools),以辅助员工利用其专业知识评估AI在各领域的适用性,并确定最佳应用场景。对于一个应用案例,若已经进行审慎分析及风险利益的权衡,拥有用于模型训练和效果评估数据集,且具备专业知识和资源的支持,下一步则是明确并验证人工智能解决方案。

实验
新的AI产品和框架发布频繁,各有工具和声明。通过实验,可以让员工和用户测试特定用例、模型和数据,记录性能表现,建立质量基线和标准。这是实施之前的必要步骤,虽然一些NLP任务公布的性能指标达到95-99%的准确率范围,但在处理图博档数据时,这些指标往往却难以达到。因此需要为图博档机构的大多数人工智能用例建立质量基线。
基线标准通过测试大量支持用例的机器学习方法,详细分析结果得出。除了全面的性能测试,还必须建立质量审查流程。AI输出须由员工和用户进行审查,以确保其在图博档机构中足够好用。还应确认自动化结果与组织的原则和目标一致。通过员工和用户对特定用例的共同测试,不仅收集了重要的反馈,还有助于培养AI结果评估的专业能力。我们采用以下机制和工具进行实验:
- “数字创新无限量交付合同”( Digital Innovation Indefinite Delivery Indefinite Quantity)是一个多年的合同机制,我们利用它来完成国会图书馆的个别AI实验,包括可能的对更广泛社区有价值的需求。
- “数据处理计划”( Data Processing Plan)文件记录了特定任务的数据转换、预测和AI模型实际性能。它结合了模型卡片、数据封面和文件馆藏来源的元素。作为数字创新无限量交付合同的一部分,供应商必须填写。
- 开发过程中的NLP供应商评估指南,和质量审查建议。
- 建议准备平衡数据集,用于对最新可用的人工智能模型和工具进行基准测试。
实验在不同风险级别下,以迭代、循环的方式,按照不同的顺序和阶段进行。验证AI所声称的性能或优势能否实现,是实验过程中至关重要的一步。
实施
员工、合作伙伴、决策者、利益相关者和供应商都期望借助AI技术,解决图博档在管理和利用数据方面长期存在的难题。然而,正如所有新兴的、潜在的颠覆性技术一样,立即实施并不切实际。图书馆对用户、利益相关者、社区和纳税人负有责任。实施阶段所详细阐述的高级别活动在实践中可能会更广泛,但在不同的组织环境下可能存在差异。通常情况下,当某项实验被确定为优先实施项目,并经过验证证明其成功与可行性,同时建立了相应的质量标准基线后,实施负责任的AI将会得到以下支持:
- AI路线图。根据实验阶段的结果和意见制定计划,用于估计管理成本、IT基础设施、采购工具,并需要持续的开发周期支持实施。
- 对AI模型及其输出进行持续测试。随着AI模型处理更多数据,结果可能会发生变化。必须建立性能目标、质量标准和用户体验目标,并对其进行监测。需要对模型的资源和计划进行审查,以确保其随着时间推移的表现符合预期。可能需要不断反馈或者微调来维持期望水平。
- 面向员工和用户。吸纳有机器学习专业知识的员工,为现有员工提供培训和经验支持。启动用户研究和参与项目,收集公众对AI工具的反馈。
- 持续社区参与和合作。协调并支持图博档机构建立共享的应用案例和数据质量标准。为图博档机构提供特定的共享数据集和工具,用于培训、基准测试和质量审查。
没有任何组织能够独自应对人工智能的变革与影响。图博档机构有机会共同开发有效、有用、且符合伦理的AI应用模块。共同开发和沟通需求将有助于改善图博档机构的AI应用效果,共享AI政策、治理、基础设施和成本的信息也同样重要。
本人工智能规划框架建立在行业应对技术变革的丰富经验之上。随着AI解决方案的普及,本方案所列出的步骤和措施将有助于确保我们在人工智能技术兑现承诺时能够充分受益。