.png)

IFLA:人工智能对图书馆的影响及图书馆应对策略
2024年01期【本期推荐】
本文为IFLA人工智能特别兴趣小组11月20日《制定图书馆对人工智能的战略响应》V1.1版报告节选翻译。报告原文地址:https://www.ifla.org/g/ai/developing-a-library-strategic-response-to-artificial-intelligence/
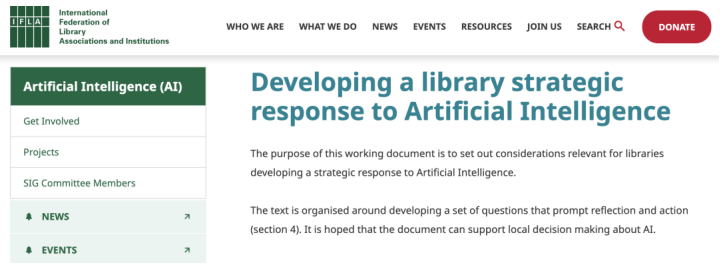
人工智能对图书馆的影响
人工智能可能对图书馆工作产生“广泛而深刻”的影响。
从下表1中我们可以看到,人工智能对图书馆诸多服务产生影响,有些带来根本性的改变,有些只带来微小的变化。预计图书馆将以符合现有角色、与用户需求紧密相关或需要最少资源的方式来应用人工智能。
我们已经强调了描述性人工智能与提高图书馆馆藏可访问性之间的紧密联系。人工智能技术被应用于生成初始元数据,此技术有望在搜索引擎中发挥作用,并助力综述的某些环节(如结果筛选)。
随着越来越多的学者在研究中使用人工智能技术,对数据科学家社区的支持需求也将增长。图书馆可以在数据发现、版权问题、数据管理和数据保存方面提供支持。
人工智能可能会改变日常的知识工作,例如自动翻译、摘要和文本生成。大量人工智能工具和应用程序可以应用于图书馆专业工作。例如ResearchRabbit、Scite、elicit和openread等工具有助于文献综述。生成式人工智能在图书馆宣传中得到了应用,因为其具备根据特定受众需求调整文本的能力。
因为人工智能能够准确执行复杂的常规性任务,故而具备了在图书馆后端系统中应用的可能。例如,采用机器人流程自动化(RPA)技术处理书目数据,便是一个典型的应用场景。
鉴于图书馆接受的咨询量大,图书馆已倡导采用聊天机器人多年。聊天机器人因为其技术障碍降低而变得可行。聊天机器人可承担如下职责:
• 回应常规问题
• 收集用户信息
• 遵循标准流程提供用户支持
• 成为新用户的伙伴
人工智能技术将被应用于打造更智能的图书馆空间。一些图书馆已研发了实体机器人用于读者咨询,机器人还被用于执行上架和盘点等任务。此外,已有图书馆采用自动存储与检索系统(ASRS),可以根据需求检索馆藏。通常,此类应用需开展大规模的重建工程。
对于学校图书馆而言,其他人工智能在教育领域的应用,如自适应学习内容创建或聊天机器人等,皆与其相关。(Jisc,2023b)。
因用户的广泛使用,生成式人工智能成为了讨论的焦点,这使得教职员工和学生需要具备一定的人工智能素养(包括数据和算法素养)。图书馆有责任推广信息素养和数字技能。人工智能素养涵盖对人工智能各种表现形式的理解,涉及“批判性评估人工智能技术;与人工智能进行有效沟通与协作;以及在网络、家庭和工作场合运用人工智能作为工具”(Long and Magerko,2020)。
人工智能素养在未来职场中显得至关重要;运用人工智能或与其协同工作的技能案例不断涌现;而其具体实施方式可能因不同学科领域而有所差异。
人工智能也可以应用于预测用户行为模式,从而辅助决策制定。
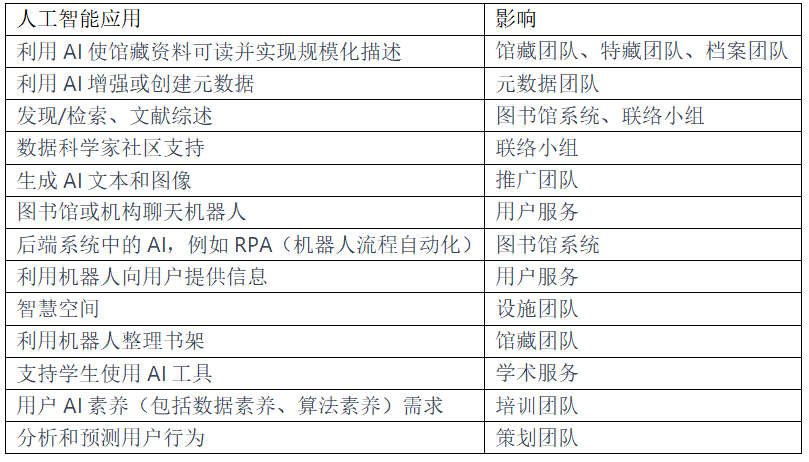
下表调查结果显示了在撰写本文时的AI发展水平。人工智能素养已迅速成为关注的焦点。(*编者注:此为根据111份样本调查数据的结果;受访者包括⾼等教育和继续教育图书馆员,主要来自英国。)
如何更新资料以跟上人工智能不断变化的特性?
哪些应用需求资源最少且最符合用户需求和现有图书馆角色?
哪些发展对重塑图书馆角色最为关键?
哪些最有可能发生,在多长时间内发生?
人工智能技术如何提升图书馆服务?人工智能能帮助解决哪些挑战?潜在的风险和伦理考虑是什么,如何减轻这些风险?
如何持续关注并及时了解新兴的人工智能的趋势和进展?
图书馆如何有效地培养用户人工智能素养?
需要哪些关键的学习成果,在各个学科中的差异性如何?
随着人工智能发生变化,教材应如何更新?
三个重要策略
鉴于人工智能影响的广泛性,图书馆可以采取多种策略以应对。以下列举三项重要策略建议。
策略一:利用图书馆的AI能力,构建负责任且可解释的描述性AI应用
在拥有大量需要改进资源描述的特色馆藏的情况下,图书馆可以应用描述性AI来创建符合伦理、负责任和可解释的AI的范例,以对抗大科技公司的产品((Lee, 2023; Padilla et al., 2023)。这可以通过遵循良好治理原则来实现,比如:
• 揭示馆藏的来源,以便使用者全面了解信息来源的性质;
• 确保应用人工智能的馆藏选择是适当的,考虑到技术和版权问题,同时尊重包容性、土著权利和非殖民化问题;尊重那些在收藏中被代表的人以及所有其他利益相关者的权利;适当奖励/认可志愿者和众包工作者;尊重知识产权问题,例如藏品中的版权/内容许可;
• 使服务对目标用户易于使用、可访问且可解释;
• 充分记录项目以确保可解释性;
• 尽可能公开地共享代码、训练数据、工具包等;
• 从可持续性角度评估项目,包括环境影响的角度
实现这一目标仍然存在许多挑战,例如如何:
• 考虑优先应用人工智能的馆藏
• 评估经济可承受的现成工具是否适用于图书馆馆藏历史数据
• 解决概念性挑战,例如如何对图像进行分类
• 将概念验证项目转化为可持续服务
策略二:利用图书馆员的数据能力增强组织的AI能力
并非所有图书馆都拥有需要使用人工智能的馆藏,但图书馆员在的数据相关领域的专长对于机构应用人工智能具有较高价值,因为当今的人工智能是数据驱动的。
这种专业知识可以支持图书馆所在的更广泛组织内的数据科学家,如学术环境中的多学科社区数据科学家,或在卫生服务或政府机构分析数据的分析师。相关行为包括:
• 在复杂的信息环境中寻找数据源
• 推广数据共享、开放性和互操作性的价值
• 解释数据来源、有效性和质量的重要性,以了解如何适当使用该数据
• 根据版权、知识产权等解释哪些数据可以使用,哪些不可以
• 使用标准描述数据及其价值
• 存储、保存(或销毁)数据
所有这些做法都符合信息治理和管理的专业知识,但需要将这些知识转化到数据领域。
策略三:推广人工智能素养以提升组织和社会的AI能力
在推广人工智能素养方面发挥领导作用,是最符合现有图书馆实践和图书馆员身份的策略,特别是在大学、学校和公共图书馆中。人们普遍认识到,公众作为公民和从业者需要了解新技术。各个专业的学生都需要这样的知识来提高就业能力。
图书馆员已经开发了信息素养项目,人工智能某些方面素养可以纳入其中。他们已经发展了所需的教学知识和技能。
人工智能素养可能包括识别人工智能何时被使用的能力;理解狭义人工智能和通用人工智能之间的差异;了解人工智能擅长解决哪些类型的问题;了解机器学习模型如何训练。另外还包括对诸如偏见、隐私、可解释性和社会影响等伦理问题的认识。
由于人工智能基于数据,因此数据素养被认为是人工智能素养的组成部分。算法素养是一个已经发展起来的概念,用于描述搜索和推荐等服务如何越来越多地由算法塑造,以使内容个性化,但也可能限制信息的可见性并产生信息茧房效应。更正式地说,它被定义为“了解在线应用、平台和服务中算法的使用,了解算法的工作原理,能够批判性地评估算法决策,以及拥有应对甚至影响算法操作的技能”(Dogruel et al, 2022: p.4)。将算法素养扩展到搜索范畴之外与人工智能素养相关。
人工智能很复杂且难以解释。它有多种应用和形态。它基于难以理解的计算思想和统计数据。通常即使是人工智能的设计者也难以理解人工智能作出的决策结果,因为机器从数据中学习模式。虽然一些人工智能的形象让我们期望去使用一个明确的AI服务(如ChatGPT),但实际上它通常嵌入在基础设施中,不容易识别或抵制。的确,可以公平地说,大型科技公司不一定希望人工智能的工作方式为人所知,因为这是商业机密。